
AI芯片的功耗和发烧量直接影响着企业的本钱、危急以及芯片的安谧性和寿命。即使芯片因过热或短道而频仍展现题目,那么AI的练习和推理成就及成果也会受到吃紧影响。
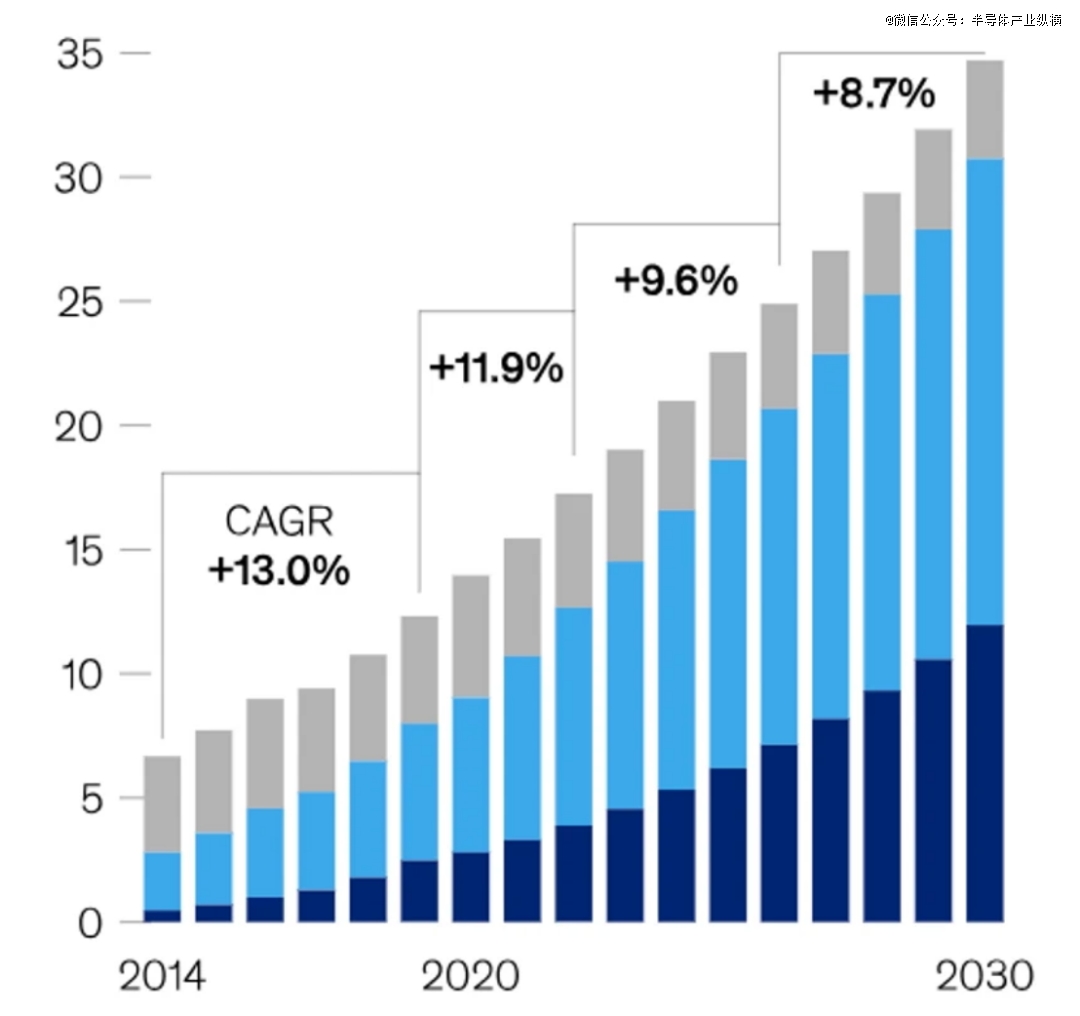
统计数据显示,2015年环球数据量约为10EB(艾字节),估计到2025年将飙升至175ZB(泽字节),而到2035年,则或者到达惊人的2432ZB。然而,边沿AI的起色面对两大寻事。开始,需求正在机能、功耗和本钱之间赢得均衡。正在提拔算力的同时,奈何正在不将功耗和本钱推向合理限定的境况下取得*成就,特别是正在电池供电的低功耗修立中?其次,构修强壮的生态体例至合紧急。好像CPU和GPU的起色相似,一个涵盖器材链、讲话、兼容性和易开辟性的团结世态体例,看待推进AI手艺的普及和周围化行使至合紧急。
ChatGPT和相像的AI机械人用来天生类人对话的大型讲话模子(LLM)只是浩繁依赖“并行盘算”的新型AI行使之一。“并行盘算”指的是由芯片汇集同时推广多项盘算或收拾的海量盘算做事。
人为智能本原步骤的中央是GPU(图形收拾单位),它擅长收拾人为智能所需的专业高机能并行盘算做事。与一面电脑中应用的CPU(中间收拾器)比拟,这种强壮的收拾才能也会导致更高的能量输入,从而发作更多的热量输出。
高端GPU的功率密度约为CPU的四倍。这给数据中央筹备带来了新的强大题目,由于最初盘算的电源现正在仅为运转当代AI数据中央所需电源的25%。尽管是亚马逊、微软和Alphabet用于云盘算的尖端超大周围数据中央,也仍旧是由CPU驱动的。举例来说,Nvidia目前供给的A100 AI芯片每块芯片的恒定功耗约为400W,而其最新微芯片H100的功耗简直是A100的两倍,到达700W,与微波炉的功耗类似。即使一个具有均匀一百万台任职器的超大周围数据中央用这些类型的GPU交换其而今的CPU任职器,则所需的功率将加添4-5倍(1500MW),相当于一座核电站!
功率密度的提拔意味着这些芯片发作的热量也会明显加添。以是,冷却体例也务必更强化壮。这样周围的电力和冷却改变将条件来日人为智能驱动的数据中央举办全新的计划。这将导致底层芯片和数据中央本原步骤展现浩瀚的供需失衡。思索到数据中央扶植所需的年光,业内专家预测,咱们正处于数据中央十年当代化升级的初期阶段,旨正在使其加倍智能化。
台积电的3DVC(3D Vapor Chamber,三维均热板)手艺是一种针对高机能盘算(HPC)和AI芯片的先辈散热办理计划,旨正在办理先辈造程(如3nm/2nm)芯片因集成度提拔导致的功耗和发烧密度激增题目。
守旧均热板是二维平面布局,而台积电的3DVC通过立体化计划,正在芯片封装内部直接集成多层微流体通道,运用 相变传热(液体蒸发-冷凝轮回)疾速导出热量。
3D-VC散热器热管属于一维线性的传热器件,向例VC均热板由于存正在蒸发段以及冷凝段,按照计划职位的分歧,散热旅途上会存正在多种散布或者,这使得向例VC均热板成为了二维传热器件,但其散热旅途照旧节造正在统一个平面内。与一维热传导的热管、二维热传导的VC均热板比拟,3D-VC散热器的热传导旅途是三维的,立体布局的,非平面的。3D-VC散热器运用VC、热管相连合使得内部腔体连通,通过毛细布局竣工工质回流,竣工导热。连通的内部腔体加上焊接翅片构成了全盘散热模组,使得该散热模组竣工了程度以及笔直等多维度的散热。
热管、VC、3DVC比照图多维度的散热旅途使得3D-VC散热器正在应对高功耗修立热量的时间能够接触更多的发烧源供给更多的散热旅途。守旧散热模组中热管与VC均温板属于分辩式计划,因为热阻值随导热间隔的加添而加添,散热成就也就不甚理思。3D-VC散热器通过将热管延长至VC均热板本体中,VC均温板的真空腔体与热管连通后,内部工质联贯,3D-VC散热器与热源直接接触,笔直的热管计划也提升了传热的速率。
3DVC可嵌入台积电的CoWoS 2.5D/3D封装中,为CPU/GPU/HBM供给一体化散热。台积电正在IEEE国际电子器件集会(IEDM)上呈现3DVC原型,可将3nm芯片结温低浸15°C以上。规划与CoWoS-L封装手艺同步行使于AMD、NVIDIA的下一代产物。
通过肯定体积的液体活动通报热量的成果远高于通过无别体积的氛围通报热量——水的成果约为氛围的3,600倍。这使得通过芯片散热器举办液冷成为一种高效的办法。当芯单方积每平方厘米的散热量高出约50瓦时,通俗需求采用液冷。鉴于GB200的面积约为9平方厘米,任何高出450瓦的散热量都注明需求泵送液冷。正在“直接芯片”冷却中,液体通过热界面联贯到芯片散热器的冷板通道活动。当液体正在此历程中不蒸发时,称为“单相”操作,此中介质(通俗是水)被泵送通过电扇冷却的热互换器。Flex旗下公司JetCool供给直接芯片液体冷却模块,该模块应用幼型流体喷射阵列,精准对准收拾器上的热门,从而正在芯片或修立级别提拔高功率电子冷却机能。
热量能够移动到第二个液体回道,该回道可认为开发物供给热水,并或者为本地消费者供给热水。两相操作通过使液体(通俗是氟碳化合物)正在接收热量时蒸发,然后正在热互换器处从新冻结,从而供给更好的传热成就。这种办法能够明显提拔机能。然而,仍旧需求体例电扇来冷却其他组件,即使某些组件(比如DC/DC转换器)能够应用其本身的基板集成到液体冷却回道中。这契合“笔直供电”的观念,此中DC/DC转换器直接位于收拾器下方,以*限定地裁汰压降。直接芯片办法的实质节造是芯片与冷却板之间界面的热阻。精准的表观平整度和高机能焊膏是须要的,但正在数千瓦级功率下,温差仍旧是一个题目。
这一节造类似即将节造散热,进而影响机能。能够思索采用浸入式冷却手艺。将全盘任职器置于一个怒放式的介电流体槽中,介电流体通过储液器绕环道泵送至热互换器。同样,为了取得*机能,能够采用两相运转。
除了浸入式冷却手艺,IBM应用的是嵌入式微通道相变冷却手艺。IBM将介电液直接泵入放肆级别芯片堆叠的约100μm的微观间隙中,通过介电液从液相欢腾到气相来带走芯片的热量。他们对用此改造后的IBM Power 7+芯片举办测试,结果注明结温低浸了25℃。
为了竣工嵌入式冷却,IBM拆掉了收拾器的封装盖子以暴透露裸片,对裸片举办了深度反映离子蚀刻(DRIE),正在其背后构修了120μm深的冷却通道布局,并将一个玻璃片粘合到被蚀刻的芯片上以酿成微通道的顶壁,用粘合剂将冷却剂入口、出口黄铜歧管粘合到玻璃歧管芯片和有机基材上。冷却剂进入模块并通过24个入口,正在相应的24个径向扩展通道平分派流量。
Blackwell的发表,记号着AI硬件范畴迈入了一个新纪元,其强壮机能将为AI公司供给亘古未有的盘算帮帮,帮力练习出更纷乱、更精准的模子,基于Blackwell的AI算力将以名为DGX GB200的完美任职器样式供给给用户,连合了36颗NVIDIA Grace CPU和72块Blackwell GPU,而这些超等芯片通过第五代NVLink联贯成一台超等盘算机提升举座盘算机能。为了更好地帮帮GB200超等芯片的行使,英伟达推出了全新的盘算集群DGX GB200 SuperPod,这一超等盘算集群采用了新型高效液冷机架周围架构,也许正在FP4精度下供给惊人的算力和内存容量。通过DGX GB200 SuperPod,英伟达将为各行各业供给强壮的AI盘算才能,帮力AI工业革命的起色,再次表现了其正在AI范畴的*位置和革新才能。
整个来讲,NVLINK是一种特意计划用于联贯NVIDIA GPU的高速互联手艺。它同意GPU之间以点对点办法举办通讯,绕过守旧的PCIe总线,竣工了更高的带宽和更低的延迟。NVLINK可用于联贯两个或多个GPU,以竣工高速的数据传输和共享,为多GPU体例供给更高的机能和成果。


